5 min to read
카프카 컨슈머 기본 개요
카프카 컨슈머 기본 개요

카프카 컨슈머는 카프카 프로듀서가 발행한 메시지를 받아서 일처리를 하는 역할을 수행한다. 메시지를 소비하는 과정에서 필요한 기본 설정들을 알아본다.
토픽 파티션, 그룹
토픽 파티션은 그룹 단위당 할당된다. 컨슈머들은 그룹 단위로 묶일 수 있으며 그룹 단위로 파티션을 할당 받는다. 파티션 갯수와 컨슈머 그룹은 밀접한 관계를 갖는다.

①: 컨슈머 그룹의 컨슈머가 1개이다. 이때 브로커의 2개의 파티션의 메시지를 읽어와 일을 수행한다.
②: 컨슈머 그룹의 컨슈머와 토픽의 파티션이 1:1 매핑되어 하나의 컨슈머가 하나의 파티션에서 메시지를 읽어와 일을 수행한다.
③: 컨슈머 그룹의 컨슈머가 1개 더 많고 파티션이 적으므로 1개의 컨슈머는 일을 수행하지 않고 논다.
위의 예시처럼 파티션 갯수와 컨슈머 그룹은 밀접환 관계가 있으며 특별한 경우가 아니라면 컨슈머의 갯수 <= 파티션의 갯수를 유지하는 설정이 좋다.
커밋과 오프셋
컨슈머가 메세지를 읽어올 때 위치를 기록하는 것이 오프셋이다.
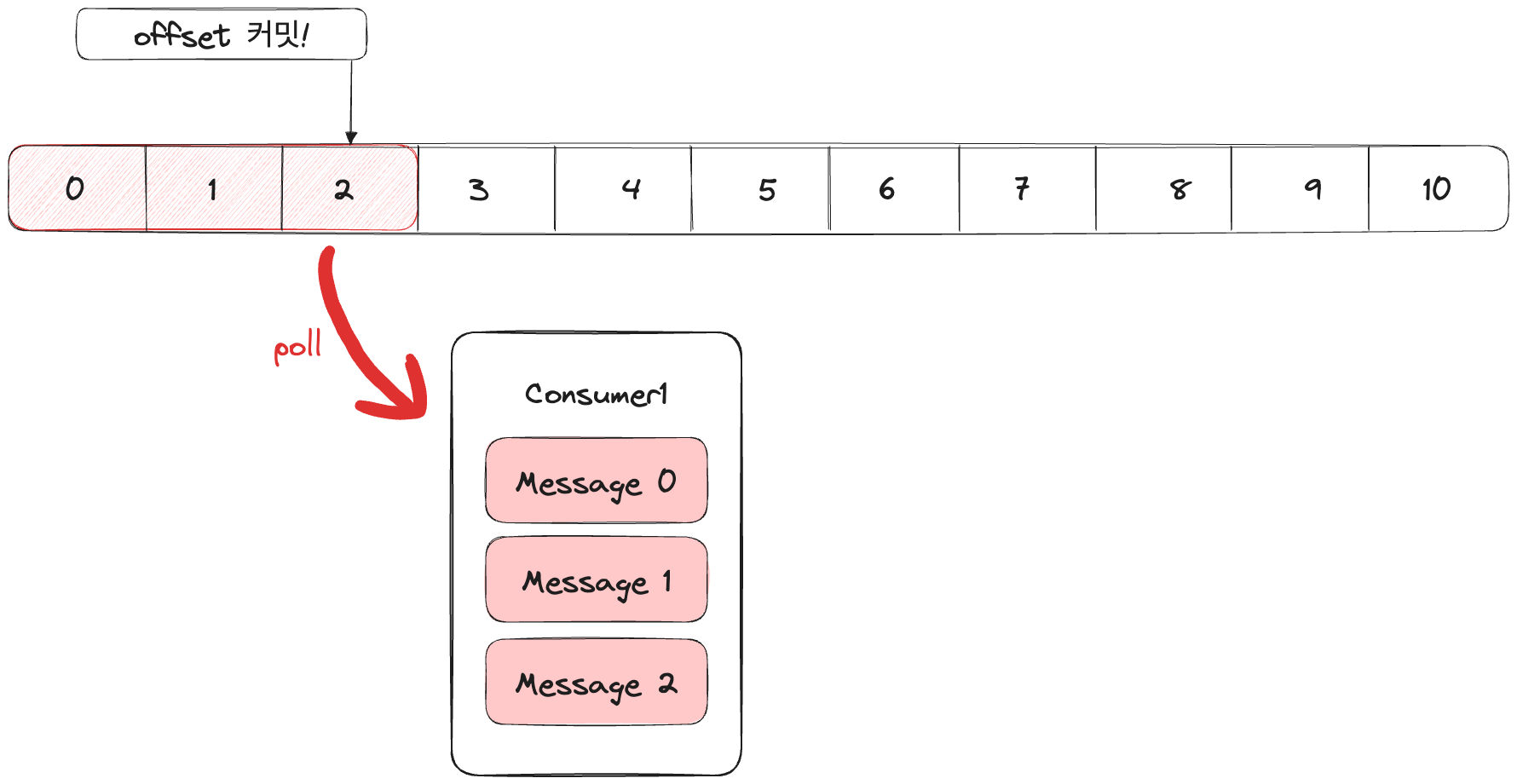
컨슈머는 0,1,2번 메시지를 읽어왔고 마지막 읽은 메시지 위치(2번)를 Offset 커밋한다.
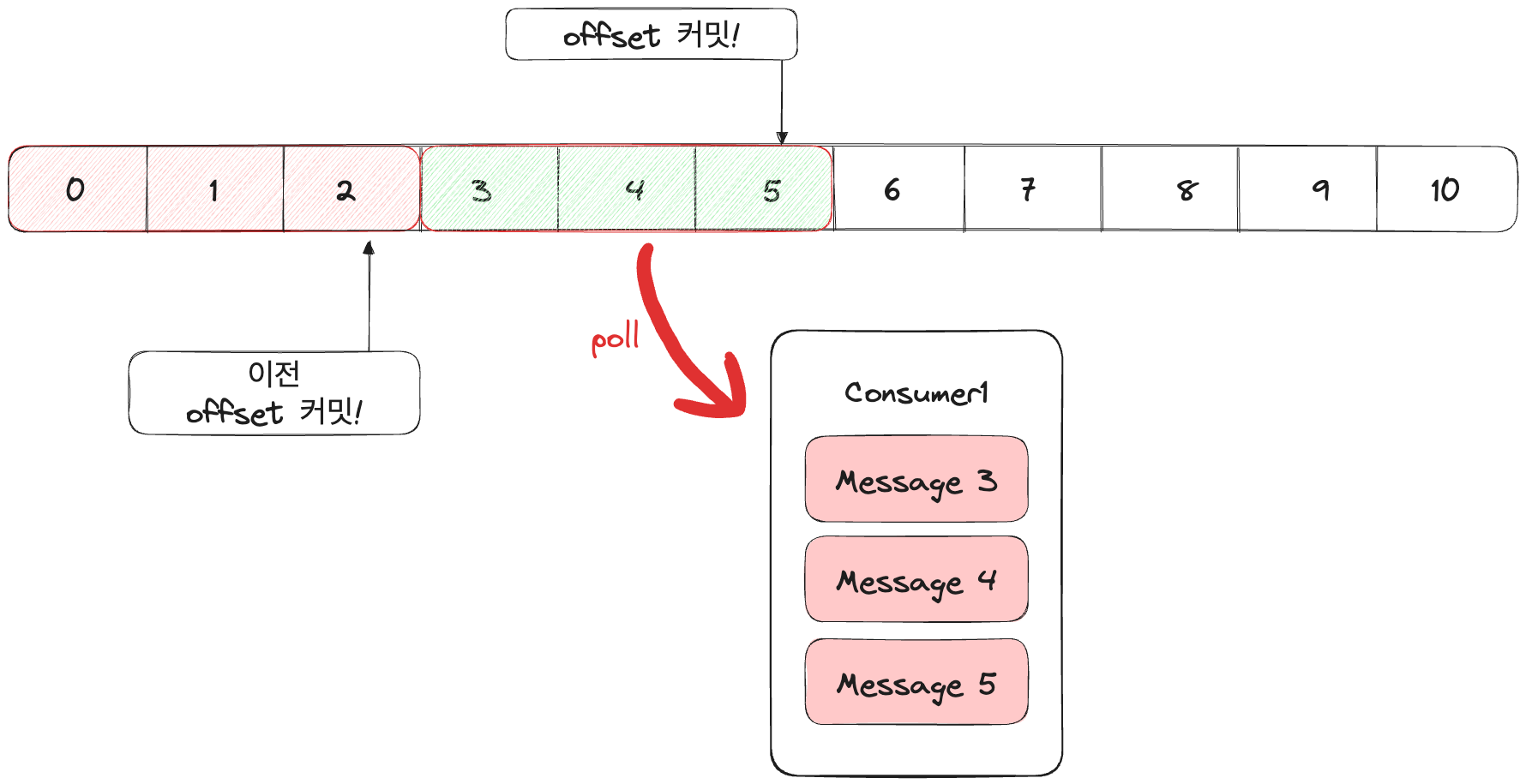
다음 메시지를 읽어올 때 Offset 기록을 참고해서 3,4,5번의 메시지를 읽어온다.
이렇게 마지막 읽은 위치를 기록하는 것을 Offest 이라 하고 브로커에서 관리한다.
커밋된 오프셋이 없는 경우
처음 접근하는 경우 or 오프셋이 없는경우에 auto.offset.reset 설정을 통해 어떻게 메시지를 읽어올 것인지 설정할 수 있다.
- earliest: 가장 처음 오프셋(0)을 사용한다.
- latest: 가장 마지막 오프셋(n)을 사용한다.(default)
- none: offset 정보가 없다면 익셉션을 발생시킨다.

컨슈머 설정
조회에 영향을 주는 주요 설정들이 있다.
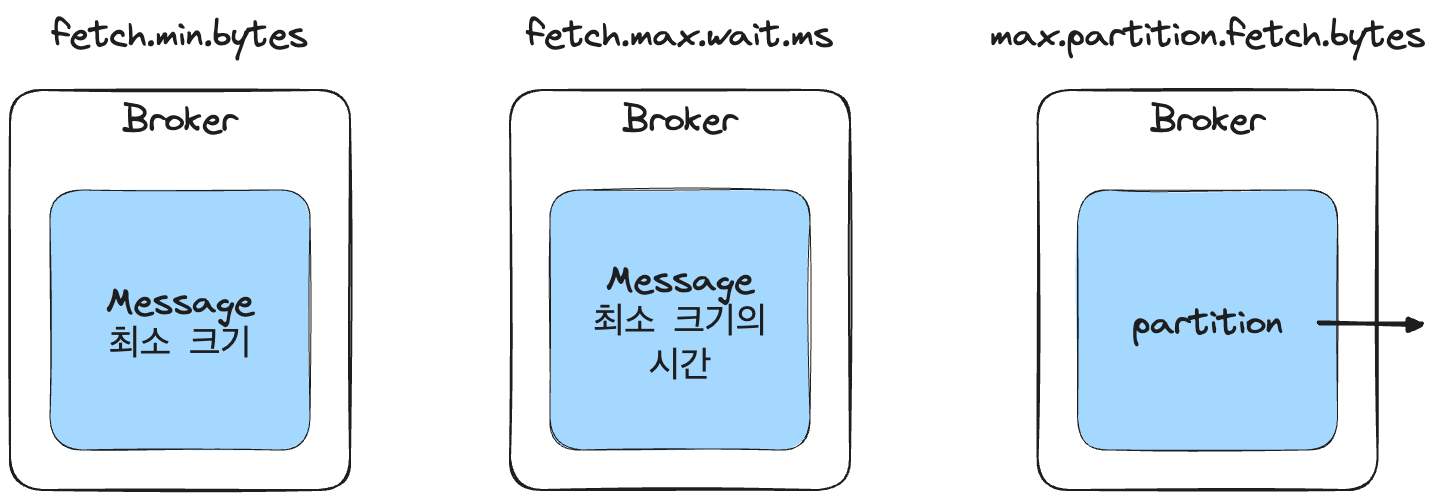
- fetch.min.bytes: 조회시 브로커가 전송할 최소 데이터 크기이다. (default: 1) 이 값이 크면 대기 시간은 늘지만 처리량은 증가한다.
- fetch.max.wait.ms: 데이터가 최소 크기가 될 때까지 기다릴 시간을 설정한다. (default: 500ms) 브로커가 리턴할 때까지 대기하는 시간으로 poll() 메서드의 대기 시간과 다르다.
- max.partition.fetch.bytes: 파티션 당 서버가 리턴할 수 있는 최대 크기를 설정한다. (default: 1MB)
자동 커밋과 수동 커밋
enable.auto.commit:
true 일정 주기로 컨슈머가 읽은 오프셋을 커밋(default)
false 수동으로 커밋 실행
auto.commit.interval.ms: 자동 커밋 주기 (default 5_000ms)
poll(), close() 메서드 호출시 자동 커밋 실행
자동 커밋의 주기를 작게 설정하여 메시지 손실 가능성을 줄일 수 있지만 그에 따라 브로커에 더 많은 부하를 줄 수 있다. 반대로 값을 크게 설정하면 브로커의 부하는 줄일 수 있지만 메시지 유실 가능성이 높아진다.
수동 커밋의 동기 / 비동기
.commitSync();: 동기
.commitAsync();: 비동기
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(e-> {/* logic.. */});
try {
consumer.commitSync();
} catch (Exception ex) {
// 커밋 실패시 에러 발생
}
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(e-> {/* logic.. */});
consumer.commitAsync(); // 추후 콜백을 받아서 처리 commitAsync(OffxsetCommitCallback callback)
동기 커밋:
- 메시지 처리의 신뢰성이 중요한 경우
- 커밋이 반드시 성공해야 하는 중요한 작업인 경우
- 메시지의 순서가 중요하거나, 메시지를 중복 처리하면 안 되는 경우
비동기 커밋:
- 높은 처리량과 성능이 중요한 경우
- 커밋 실패에 대해 유연하게 대처할 수 있는 경우
- 메시지 처리 속도가 중요하고, 일부 메시지가 중복 처리되어도 큰 문제가 없는 경우
재처리와 순서
컨슈머는 여러 이유들로 인해 메시지를 여러 번 조회할 수 있다.
동일한 메시지를 조회할 가능성에 대해 대처해야 한다.
- 일시적 커밋 실패, 리밸런스 등에 의해 발생
컨슈머는 멱등성(idempotence)을 고려 해야 한다.
동일한 작업을 여러 번 수행하더라도 결과가 변하지 않아야 한다.
- ex) 조회수 1증가 -> 좋아요 1증가 -> 조회수 1증가
- 단순 처리하면 조회수는 2가 아닌 4가 될 수도 있음
멱등성 처리 방법은 여러 방법들이 있다. 데이터 특성에 따라 타임 스탬프, 일련 번호 등을 사용하여 중복 처리에 대해 예방할 수 있다.
- 타임 스탬프: 각 메시지에 타임 스탬프를 부여하여 중복 처리 X
- 일련 번호: 고유 ID 를 부여해 메시지 중복 처리 X
세션 타임아웃, 하트비트, 최대 poll 간격
컨슈머는 브로커에게 하트비트를 전송해서 연결을 지속적으로 유지한다. 브로커는 일정 시간 컨슈머로부터 하트비트가 없으면 컨슈머를 그룹에서 빼고 리밸런스 진행한다.
session.timeout.ms: 세션 타임 아웃 시간 (default 10sec)
heartbeat.interval.ms: 하트비트 전송 주기 (default 3sec), 해당 설정은 세션 타임 아웃 시간의 1/3 이하를 추천
max.poll.interval.ms: poll() 메서드의 최대 호출 간격 이 시간이 지나도록 poll() 하지 않으면 컨슈머를 그룹에서 빼고 리밸런스 진행
종료 처리
다른 쓰레드에서 wakeup() 메서드 호출 poll() 메서드가 WakeupException 발생 -> close() 메서드로 종료 처리
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
consumer.subscribe(Collections.singleton("simple"));
try {
while (ture) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSecond(1)); // wakeup() 호출시 익셉션 발생!
/* ...records */
try {
consumer.commitAsync();
} catch (Exception e) {
/* ...exception */
}
}
} catch (Exception ex) {
/* ...exception */
} finally {
consumer.close();
}
쓰레드에 안전하지 않음
컨슈머는 쓰레드에 안전하지 않다. 여러 쓰레드에서 동시에 컨슈머 인스턴스를 사용하면 된다. 이는 컨슈머가 내부적으로 많은 상태를 유지하고 있으며, 여러 쓰레드에서 동시 접근 시 일관성을 잃을 수 있기 때문이다.
예외적으로 wakeup() 메서드는 다른 쓰레드에서 호출할 수 있다. 이 메서드는 현재 poll()을 실행 중인 쓰레드를 안전하게 깨워서 종료를 유도한다.
wakeup(): 현재 실행 중인 poll() 메서드를 즉시 중단시키고 WakeupException 을 발생시키기 위해 사용된다. 해당 메서드는 다른 스레드에서 안전하게 종료되도록 하는 유일한 방법 중 하나이다.


Comments